Вопросно-ответная система для задач компьютерного зрения (Vqa) — это интересное направление в мире искусственного интеллекта, которое объединяет алгоритмы обработки изображений и машинного обучения. Vqa позволяет компьютеру отвечать на вопросы, связанные с содержимым изображений.
Основная цель Vqa — развить возможности компьютера в понимании содержания изображений, подобно тому, как это делает человек. Для этого Vqa использует сложные алгоритмы, обрабатывающие графическую информацию и анализирующие ее с помощью нейронных сетей.
Как это работает? Система Vqa берет изображение в качестве входных данных и анализирует его содержимое с помощью алгоритмов компьютерного зрения. Затем система формулирует вопрос, связанный с изображением, и передает его в алгоритмы машинного обучения. Алгоритмы машинного обучения анализируют вопрос и содержимое изображения, чтобы дать наиболее точный и информативный ответ на вопрос.
Интересно отметить, что система Vqa может не только отвечать на вопросы, но и обучаться на основе предыдущих ответов. Это позволяет системе Vqa улучшать свои навыки и становиться все более точной и эффективной в своей работе.
Что такое VQA и зачем оно нужно?
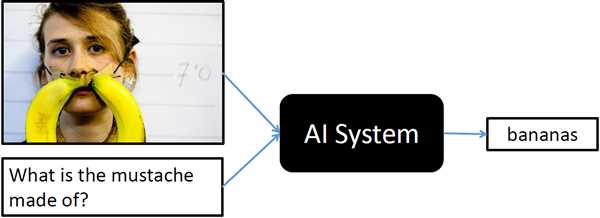
Зачем нужно VQA? Ответ на этот вопрос заключается в возможностях, которые предоставляет данная технология. Благодаря алгоритмам машинного обучения, VQA позволяет компьютерам с видением понимать содержимое изображений и отвечать на вопросы, связанные с ними. Для этого системе предоставляются изображение и текстовый вопрос о нем. VQA сочетает алгоритмы компьютерного зрения для анализа изображения и алгоритмы обработки естественного языка для понимания и формулирования ответа на вопросы.
Применение VQA может быть полезным в различных областях, таких как автономные автомобили, медицина, электронная коммерция и т.д. Например, в автономных автомобилях VQA может использоваться для определения состояния дороги или распознавания дорожных знаков. В медицине VQA может помочь в диагностике и анализе медицинских изображений. В электронной коммерции VQA может использоваться для улучшения поиска товаров на основе визуальных запросов.
Роль машинного зрения в VQA
Машинное зрение играет ключевую роль в системе VQA (вопрос-ответ на изображении), позволяя компьютеру видеть и анализировать изображения, чтобы отвечать на вопросы о них.
Машинное зрение — это подраздел искусственного интеллекта, который разрабатывает алгоритмы и модели, позволяющие компьютеру анализировать и интерпретировать изображения так же, как это делает человек с помощью своего зрения.
В задаче VQA, машинное зрение используется для анализа визуальных признаков изображений, распознавания объектов, сцен, контекста и прочей информации, которая может помочь в ответе на вопросы о изображении.
Процесс работы машинного зрения в VQA может включать в себя следующие шаги:
- Обнаружение и распознавание объектов на изображении
- Извлечение признаков из изображения
- Анализ контекста и сцены на изображении
- Оценка важности и релевантности визуальных признаков для конкретного вопроса
Благодаря машинному зрению, системы VQA могут более точно и полно отвечать на вопросы о изображениях, учитывая все доступные визуальные информации.
Использование машинного зрения в VQA позволяет не только расширить возможности и точность ответов системы, но и сделать интерфейс более удобным и естественным для пользователей, позволяя им задавать вопросы о изображении с помощью естественного языка, вместо использования сложных команд или ключевых слов.
|
Процесс работы VQA: шаг за шагом Одним из ключевых направлений искусственного интеллекта является разработка систем машинного зрения, способных понимать и анализировать изображения. Но чтобы эта система могла взаимодействовать с пользователем, она должна уметь отвечать на вопросы о содержимом этих изображений. Вот для решения этой задачи и создана технология VQA (Visual Question Answering). Процесс работы VQA можно разделить на несколько шагов:
Для решения задачи VQA применяются различные методы, включая нейронные сети и глубокое обучение. Эти методы позволяют обучить систему VQA распознавать объекты на изображениях и отвечать на вопросы о них. В результате получается инновационная и полезная технология, способствующая развитию искусственного интеллекта и машинного зрения. |
Обучение VQA модели: основные этапы
Процесс обучения модели VQA включает несколько этапов:
1. Подготовка данных:
Перед началом обучения модели необходимо подготовить тренировочные данные. Это может включать в себя написание алгоритмов для извлечения визуальных и текстовых данных, их предобработку и преобразование в удобный для модели формат.
2. Выбор архитектуры модели:
Следующим шагом является выбор и настройка архитектуры модели. Здесь важно учитывать особенности задачи VQA, включая многообразие вопросов и типов изображений. Возможные архитектуры могут включать сверточные нейронные сети (CNN) для анализа изображений и рекуррентные нейронные сети (RNN) для обработки вопросов и генерации ответов.
3. Обучение модели:
На этом этапе происходит фактическое обучение модели с использованием подготовленных данных и выбранной архитектуры. Обучение может быть осуществлено с использованием различных алгоритмов машинного обучения, таких как градиентный спуск или алгоритм обратного распространения ошибки.
4. Оценка качества модели:
После завершения обучения модели необходимо оценить ее качество. Это можно сделать путем проверки модели на отложенных данных или с помощью метрик, таких как точность или показатель F1-score.
В целом, обучение VQA модели требует как адаптации алгоритмов компьютерного зрения для анализа изображений, так и обработки естественного языка для понимания и генерации ответов на вопросы. Комбинирование этих компонентов позволяет создать модель, способную отвечать на разнообразные вопросы, связанные с изображениями.
Основные алгоритмы машинного зрения, используемые в VQA
1. Классификация изображений
Один из основных алгоритмов, используемых в VQA, — это классификация изображений. Этот алгоритм обучает модель распознавать различные объекты и характеристики на изображении. На основе этого обучения модель может понять, что есть на изображении и какие объекты могут быть связаны с заданным вопросом.
2. Обнаружение объектов
Еще один важный алгоритм, используемый в VQA, — это обнаружение объектов на изображении. Этот алгоритм использует различные методы, такие как нейронные сети, чтобы идентифицировать и выделить объекты на изображении. Такая информация может быть полезна для понимания содержимого изображения и ответа на соответствующие вопросы.
3. Глубокое обучение
Еще один важный алгоритм, используемый в VQA, — это глубокое обучение. Этот алгоритм позволяет модели автоматически извлекать важные характеристики из изображений и использовать их для определения ответа на вопросы. Глубокое обучение может быть применено как к изображениям, так и к текстовой информации, позволяя модели адаптироваться к разным типам вопросов и изображений.
Все эти алгоритмы машинного зрения совместно работают для решения задачи VQA. Путем объединения информации изображений и вопросов, система VQA может дать точные и понятные ответы на вопросы, основанные на его анализе и понимании визуального контента.
Как VQA модель понимает вопрос и изображение?
Рабочий процесс модели VQA включает несколько шагов:
- Извлечение признаков изображения: используя предварительно обученную модель компьютерного зрения, VQA модель извлекает признаки изображения. Эти признаки представляют важные аспекты и характеристики изображения.
- Извлечение признаков вопроса: текстовое представление вопроса преобразуется в числовую форму, чтобы модель могла понять и обработать его. Этот шаг включает в себя кодирование текста в численный вектор.
- Объединение признаков: путем объединения признаков изображения и признаков вопроса, модель создает объединенное представление, которое содержит информацию как о вопросе, так и о изображении.
- Обучение и классификация: VQA модель использует объединенное представление для обучения и классификации ответов на основе доступных вариантов ответов. Она обучается понимать связь между вопросом, изображением и правильным ответом.
- Генерация ответа: после обучения VQA модель может генерировать ответ на вопрос, основываясь на взаимодействии вопроса и изображения. Она предоставляет ответ в текстовой форме, который наилучшим образом соответствует содержанию изображения.
Таким образом, VQA модель способна комбинировать знания о изображении и контексте вопроса, чтобы сформулировать осмысленный ответ на основе содержания. Она использует совместное обучение и классификацию, чтобы научиться понимать связь между вопросом и изображением, что позволяет ей генерировать ответы на вопросы, заданные в текстовой форме.
Технологии глубокого обучения в VQA
Глубокое обучение — это подход к машинному обучению, основанный на использовании искусственных нейронных сетей. Эти нейронные сети обучаются автоматически анализировать данные и принимать решения на основе полученной информации. В VQA глубокое обучение используется для обработки изображений и получения ответов на заданные вопросы.
Алгоритмы, используемые в VQA, включают в себя сверточные нейронные сети (Convolutional Neural Networks, CNN) и рекуррентные нейронные сети (Recurrent Neural Networks, RNN). Сверточные нейронные сети применяются для анализа и классификации изображений, в то время как рекуррентные нейронные сети используются для обработки последовательностей данных, таких как текст вопросов.
В процессе работы VQA, алгоритмы глубокого обучения преобразуют входные изображения и текстовые вопросы в числовые представления, которые затем передаются в нейронную сеть для вычисления ответов. Нейронная сеть обучается на наборе данных, содержащем пары изображений и соответствующих им вопросов и ответов. После обучения, система может генерировать ответы на вопросы, основываясь на полученных данных и своих предсказаниях.
Технологии глубокого обучения, такие как машинное обучение и алгоритмы нейронных сетей, вносят значительный вклад в развитие и улучшение систем VQA. Они позволяют системам обрабатывать и анализировать сложные данные, такие как изображения, и генерировать точные и информативные ответы на заданные вопросы.
Примеры применения VQA в реальной жизни
Алгоритмы обработки изображений и компьютерного зрения, используемые в системе VQA, находят широкое применение в различных сферах жизни.
Например, в медицине VQA может быть использована для анализа медицинских изображений. С помощью VQA алгоритмы могут сопоставлять изображения с базой данных и давать рекомендации по диагнозу или плану лечения. Это особенно полезно при идентификации различных заболеваний или при выявлении аномалий на изображении, которые могут быть незаметны для человеческого глаза.
В сфере безопасности VQA может использоваться для анализа видеоизображений с камер наблюдения. Алгоритмы VQA могут автоматически обнаруживать и классифицировать различные объекты или ситуации, например, опасные предметы или агрессивное поведение. Это позволяет работнику безопасности быстро отреагировать на возможную угрозу и принять меры предосторожности.
В области рекламы и маркетинга VQA может использоваться для анализа изображений, размещаемых в рекламных кампаниях. Алгоритмы VQA могут определить, какие изображения вызывают наибольший отклик у потребителей, и помочь компаниям оптимизировать свои рекламные сообщения.
Кроме того, VQA может быть использована в автоматизации процессов, например, в промышленности или логистике. Системы VQA могут автоматически анализировать и классифицировать изображения, что позволяет сократить время и ресурсы, затрачиваемые на выполнение повторяющихся задач.
В целом, VQA представляет собой мощный инструмент, который может быть применен во многих отраслях для автоматического анализа и понимания изображений.
Основные преимущества и недостатки VQA
Метод VQA (Visual Question Answering) объединяет области машинного зрения и обработки естественного языка, позволяя машинам отвечать на вопросы, связанные с изображениями. Такое взаимодействие между компьютером и человеком имеет свои преимущества и недостатки.
Преимущества
1. Расширение возможностей машинного зрения: VQA позволяет получить дополнительную информацию об изображении, что помогает расширить возможности алгоритмов машинного зрения. Модель способна понимать содержимое изображения, а также отвечать на вопросы о нём.
2. Более глубокое взаимодействие с пользователем: VQA позволяет улучшить взаимодействие пользователя с машиной. Можно задавать вопросы об изображении и получать ответы, что особенно удобно в ситуациях, когда необходимо отобрать изображения по определенным параметрам.
3. Возможность создания полезных приложений: VQA находит применение во многих сферах, таких как медицина, автоматизация и технологии безопасности. С его помощью можно создать полезные приложения, например, системы контроля погоды или врача-компьютера, способного отвечать на вопросы о состоянии пациента на основе изображений.
Недостатки
1. Точность ответов: Несмотря на то, что VQA достиг высоких показателей точности, она все еще может допускать ошибки или предлагать неправильные ответы. Это связано с сложностью задачи и естественными ограничениями алгоритмов.
2. Зависимость от качества изображений и вопросов: VQA результаты сильно зависят от качества изображений и формулировок вопросов. Низкое качество изображений или неправильно сформулированные или двусмысленные вопросы могут вызвать некорректные ответы от системы.
3. Ограничения масштаба: Системы VQA требуют больших вычислительных ресурсов и объемных наборов данных для обучения, что ограничивает их применение. Это делает VQA сложной задачей для реализации в условиях ограниченных ресурсов или на устройствах с ограниченной вычислительной мощностью.
В целом, VQA имеет большой потенциал для улучшения взаимодействия машины с пользователем и расширения возможностей машинного зрения. Однако, существующие недостатки указывают на необходимость дальнейших исследований и улучшений в данной области.